
python爬取百度贴吧源码
大小:4.4M更新:2019-07-19
类别:源码相关系统:WinXP,Win7,win8
分类
大小:4.4M更新:2019-07-19
类别:源码相关系统:WinXP,Win7,win8
python爬取百度贴吧源码,由吾爱大神原创制作,通过python爬虫程序来实现对百度贴吧的回复爬取,可以自动生成excel文件,让你能更加清晰地查看贴吧的回复与帖子信息。本次放出python爬取百度贴吧源码数据资源下载,并提供webdriver加载程序,安装后可以让源码加载到谷歌浏览器上运行,有相关百度贴吧爬取需求的朋友们不妨试试吧!

webdriver
BeautifulSoup
xlwt
time(自带)
需要 chromedriver.exe 并配置环境变量,可能需要对应版本,百度可解决
当前适用于 Chrome版本 74.0.3729.131(正式版本)(32 位)
主函数中配置登录账号(line 91)
在提示“请输入任意内容确认你已经登录:“
必须是你已经登录账号,
出现验证码请手动处理。(line 92)
(ilne 93) 输入你要打开回复的第几页
最后一个数字是页数,不写为第一页
生成的 excel 超链接没有样式
excel样式需要自己添加(后续版本改进)
# http://tieba.baidu.com/i/i/my_reply
from selenium import webdriver
import time
from bs4 import BeautifulSoup
import xlwt
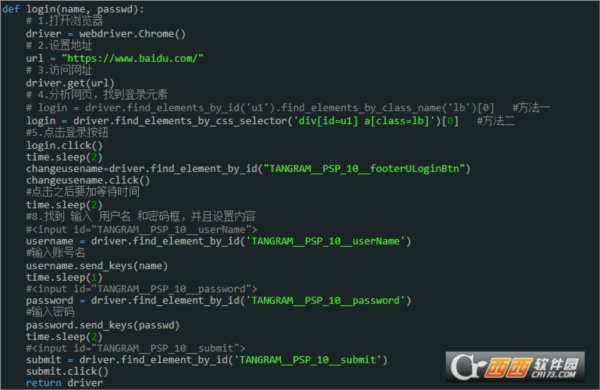
def login(name, passwd):
# 1.打开浏览器
driver = webdriver.Chrome()
# 2.设置地址
url = "https://www.baidu.com/"
# 3.访问网址
driver.get(url)
# 4.分析网页,找到登录元素
# login = driver.find_elements_by_id('u1').find_elements_by_class_name('lb')[0] #方法一
login = driver.find_elements_by_css_selector('div[id=u1] a[class=lb]')[0] #方法二
#5.点击登录按钮
login.click()
time.sleep(2)
changeusename=driver.find_element_by_id("TANGRAM__PSP_10__footerULoginBtn")
changeusename.click()
#点击之后要加等待时间
time.sleep(2)
#8.找到 输入 用户名 和密码框,并且设置内容
#<input id="TANGRAM__PSP_10__userName">
username = driver.find_element_by_id('TANGRAM__PSP_10__userName')
#输入账号名
username.send_keys(name)
time.sleep(1)
#<input id="TANGRAM__PSP_10__password">
password = driver.find_element_by_id('TANGRAM__PSP_10__password')
#输入密码
password.send_keys(passwd)
time.sleep(2)
#<input id="TANGRAM__PSP_10__submit">
submit = driver.find_element_by_id('TANGRAM__PSP_10__submit')
submit.click()
return driver
def opentieba(browser, url = 'http://tieba.baidu.com/i/i/my_reply?&pn=1'):
browser.get(url)
context=browser.page_source
soup = BeautifulSoup(context, 'html.parser')
context=browser.find_element_by_css_selector(".simple_block_container")
print(context.text)
cont=soup.find_all(class_='b_right_up')
return cont
def writeXls(cont):
i = 0 # 从第几行开始写
# 1、导入模块
# 2、创建workbook(其实就是excel,后来保存一下就行)
# workbook = xlwt.Workbook(encoding='ascii')
workbook = xlwt.Workbook(encoding = 'utf-8')
# 3、创建表
worksheet = workbook.add_sheet('sheet1')
for link in cont:
print(link)
item = BeautifulSoup(str(link), 'html.parser')
reply_context=item.find(class_="for_reply_context")
thread_title=item.find(class_="thread_title")
href = str(thread_title)[31:54]
href = 'http://tieba.baidu.com/' + href
print(reply_context.text)
worksheet.write(i, 0, label=reply_context.text)
print(thread_title.text)
worksheet.write(i, 1,xlwt.Formula('HYPERLINK("'+href+'"," '+thread_title.text+'")'))
print(href)
i = i + 1
time.sleep(1)
# 5、保存
date = time.strftime("%Y%m%d%H%M%S", time.localtime())+ '_'
workbook.save('Excel_'+date+str(i)+'.xls')
i = 0
return "successful"
def writedata(data):
#1、导入模块
#2、创建workbook(其实就是excel,后来保存一下就行)
workbook = xlwt.Workbook(encoding='ascii')
# 3、创建表
worksheet = workbook.add_sheet('sheet1')
#4、往单元格内写入内容
worksheet.write(0, 0, label=data)
# 5、保存
workbook.save('Excel_Workbook.xls')
def main():
driver = login("美食拍客136822", "*****")
str = input("请输入任意内容确认你已经登录:")
xlscontext = opentieba(driver, url = 'http://tieba.baidu.com/i/i/my_reply?&pn=1')
res = writeXls(xlscontext)
print(res)
if __name__ == '__main__':
main()
 Halo博客系统查看
Halo博客系统查看 2016最新易语言刷屏骂人软件源码查看
2016最新易语言刷屏骂人软件源码查看 酒吧微上墙全开源模块查看
酒吧微上墙全开源模块查看 CmsEasy易通企业网站管理系统查看
CmsEasy易通企业网站管理系统查看 discuz x3.2 utf8模板查看
discuz x3.2 utf8模板查看 阿里icon图标gulp插件gulp-qc-iconfont查看
阿里icon图标gulp插件gulp-qc-iconfont查看 瑾北二次开发QQ技术网址导航源码查看
瑾北二次开发QQ技术网址导航源码查看 PHP交友类型网站源码(附APP源码)查看
PHP交友类型网站源码(附APP源码)查看 彩虹云任务秒评网站源码查看
彩虹云任务秒评网站源码查看 在线无水印视频解析下载源码查看
在线无水印视频解析下载源码查看 沉沦云全套扫码加速源码查看
沉沦云全套扫码加速源码查看 jquery特效编写js库查看
jquery特效编写js库查看 全网视频搜索VIP解析工具源码查看
全网视频搜索VIP解析工具源码查看 HTML5扫雷游戏源码查看
HTML5扫雷游戏源码查看 茶云导航源码(带后台)查看
茶云导航源码(带后台)查看 本地密码管理器开元程序查看
本地密码管理器开元程序查看 中文DOS游戏(Chinese DOS games in browser)项目源码查看
中文DOS游戏(Chinese DOS games in browser)项目源码查看 2020最新正版香橙互赞宝源码查看
2020最新正版香橙互赞宝源码查看 码支付系统-浓域系统免签约支付内附教程软件带轮询功能查看
码支付系统-浓域系统免签约支付内附教程软件带轮询功能查看 笔趣阁小说源码查看
笔趣阁小说源码查看 GIt离线储存库管理器GitAhead查看
GIt离线储存库管理器GitAhead查看 XyPlayer智能解析源码查看
XyPlayer智能解析源码查看 四十余套微信商城小程序完整源码查看
四十余套微信商城小程序完整源码查看 CakePHP专业php开发框架查看
CakePHP专业php开发框架查看易语言360云盘容量一键扩充4T软件源码源码相关.64M免费版
查看物理硬盘逻辑锁骷髅头美化版源码源码相关.00M免费版
查看易语言QQ工具箱源码源码相关M
查看Java实战之学生管理系统模板源码相关M免费版
查看开运网测算源码安装包源码相关M免费版
查看CF备上市外部绘制变态辅助源码源码相关M免费版
查看畅易阁网游交易-全自动辅助工具源码源码相关.92M最新版
查看支付宝监控系统易语言源码源码相关.68M最新版
查看花锦绝地求生一键大跳助手源码源码相关.29MV1.3绿色版
查看NSFW JS图片鉴别工具源码源码相关M
查看制作QQ业务网站平台源码源码相关.70M最新免费版
查看星尘UI源码和素材源码相关Mv1.3wordpress小程序
查看discuz x3.2 gbk正式版源码相关Mv20151208 简体中文官方版
查看粒子动态特效字体引导页源码源码相关M首发版
查看dede织梦cms资源网模板源码源码相关M
查看京东图床外链瀑布php源码源码相关.39M最新版
查看Emlog小刀娱乐网模板源码源码相关M
查看班级签到系统(网课签到)源码相关.01M
查看IP签名动态图显示程序源码相关M
查看ssh三大框架(struts+spring+hibernate)源码相关M最新免费版
查看高级资源类WordPress主题(ripro)源码相关MV6.2.0去授权版
查看ncm解密源码(python)源码相关.00M
查看零点城市社交电商源码源码相关Mv1.73 商业无限开版
查看终结者D3D画框透视源码源码相关.09M最新可用的
查看点击查看更多






















