python爬取半次元图片源码
大小:.00M更新:2019-07-24
类别:源码相关系统:WinXP,Win7,win8
分类
大小:.00M更新:2019-07-24
类别:源码相关系统:WinXP,Win7,win8
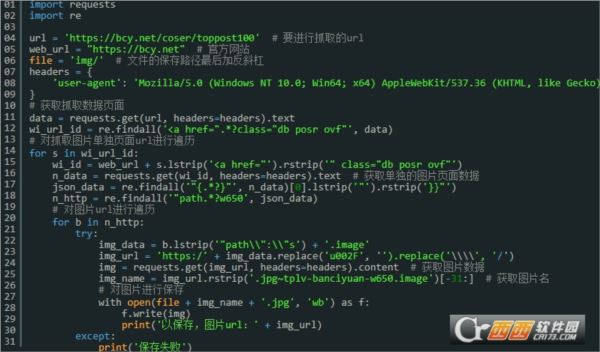
python爬取半次元图片源码,由大神自制的python爬取工具,本源码针对半次元图片平台,可以爬取最新的网站图片资源,支持自定义保存目录,非常方便,需要requests库的支持,想要相关源码资源的朋友们不要错过哦!

需要安装requests库,在运行脚本的文件夹下新建一个img文件夹
源码也可供大家学习和参考。
import requests
import re
url = 'https://bcy.net/coser/toppost100' # 要进行抓取的url
web_url = "https://bcy.net" # 官方网站
file = 'img/' # 文件的保存路径最后加反斜杠
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
# 获取抓取数据页面
data = requests.get(url, headers=headers).text
wi_url_id = re.findall('<a href=".*?class="db posr ovf"', data)
# 对抓取图片单独页面url进行遍历
for s in wi_url_id:
wi_id = web_url + s.lstrip('<a href="').rstrip('" class="db posr ovf"')
n_data = requests.get(wi_id, headers=headers).text # 获取单独的图片页面数据
json_data = re.findall('"{.*?}"', n_data)[0].lstrip('"').rstrip('}}"')
n_http = re.findall('"path.*?w650', json_data)
# 对图片url进行遍历
for b in n_http:
try:
img_data = b.lstrip('"path\\":\\"s') + '.image'
img_url = 'https:/' + img_data.replace('u002F', '').replace('\\\\', '/')
img = requests.get(img_url, headers=headers).content # 获取图片数据
img_name = img_url.rstrip('.jpg~tplv-banciyuan-w650.image')[-31:] # 获取图片名
# 对图片进行保存
with open(file + img_name + '.jpg', 'wb') as f:
f.write(img)
print('以保存,图片url:' + img_url)
except:
print('保存失败')
 PHPMaos小说采集系统查看
PHPMaos小说采集系统查看 易语言超星尔雅全自动刷课源码查看
易语言超星尔雅全自动刷课源码查看 二次元风格好看的视频解析官网html源码查看
二次元风格好看的视频解析官网html源码查看 易语言引号处理E源码查看
易语言引号处理E源码查看 CF很火的N9人物透视驱动源码查看
CF很火的N9人物透视驱动源码查看 微软全局订阅A3桌面版office账号自助申请程序查看
微软全局订阅A3桌面版office账号自助申请程序查看 luck2017公司抽奖源码查看
luck2017公司抽奖源码查看 音乐网搭建源码加视频教程查看
音乐网搭建源码加视频教程查看 C#解除端口占用源码查看
C#解除端口占用源码查看 网络内存数据器(Apache Ignite)查看
网络内存数据器(Apache Ignite)查看 新拟态化风格个人导航单页HTML源码查看
新拟态化风格个人导航单页HTML源码查看 YY全自动蹲点加好友软件源码查看
YY全自动蹲点加好友软件源码查看 淘宝客工具箱查看
淘宝客工具箱查看 电脑锁机软件源码【易语言】查看
电脑锁机软件源码【易语言】查看 迷你世界全套辅助源码查看
迷你世界全套辅助源码查看 CF备上市外部绘制变态辅助源码查看
CF备上市外部绘制变态辅助源码查看 方舟编译器查看
方舟编译器查看 3款刺激战场腾讯模拟器辅助源码查看
3款刺激战场腾讯模拟器辅助源码查看 在线VIP视频解析源码查看
在线VIP视频解析源码查看 ajax实战入门模板查看
ajax实战入门模板查看 PESCMS TEAM开源任务管理系统查看
PESCMS TEAM开源任务管理系统查看 PHP直播资源自动采集源码查看
PHP直播资源自动采集源码查看 很有意思的后台防盗源码查看
很有意思的后台防盗源码查看 高仿QQ音乐UI-iapp源码查看
高仿QQ音乐UI-iapp源码查看牛来了特殊棋牌源码(附教程)源码相关M
查看朋友圈尖叫字体生成工具源码源码相关M
查看niRvana主题破解版源码相关M3.1
查看码支付系统-浓域系统免签约支付内附教程软件带轮询功能源码相关MV1.0新版易语言源码
查看腾讯微视刷播放量软件源码源码相关Mpc版
查看斑马易语言源代码段管理器源码相关.64MV2.4绿色版
查看Force Yc Dlbrush个人发卡系统源码源码相关Mv1.0.5
查看彩虹业务社区安卓版E4A源码源码相关.65M最新版
查看天雷YY多功能协议易语言源码源码相关M免费版
查看PHP仿A8音乐分享网站源码源码相关M带会员功能
查看SEO蜘蛛程序源码源码相关.04M
查看Java迷宫实战模板源码相关.02M免费版
查看OSPE抓包工具源码相关.80Mv1.1.1 免费版
查看宏仔杂货商城小店源码源码相关M全网首发
查看帝国CMS仿前瞻头条文章网站源码源码相关Mv7.2 内核92GAME
查看微素达微信编辑器-微信公众平台编辑器源码源码相关M官方绿色版
查看python多线程爬取人人影视视频源码源码相关.00M
查看QQ群助手软件源码源码相关M2016最新免费版
查看非常好看的网站域名出售模板html5源码源码相关.09M最新免费版
查看HT易支付系统源码源码相关Mv4.9全解版
查看Emlog小刀娱乐网模板源码源码相关M
查看微擎微赞通用功能模块:人人商城EWEI_SHOP源码相关Mv3 3.14.20
查看SSH5登录功能源码源码相关M框架整合
查看点击查看更多