tesseract-ocr中文版
4.0.0 官方安装版大小:41.9M更新:2018-03-15
类别:办公软件系统:WinAll,Win7,win8
分类
大小:41.9M更新:2018-03-15
类别:办公软件系统:WinAll,Win7,win8
TesseractOCR,可以直接将图片中的文字进行识别,其最新版本3.0已经支持中文OCR,并提供了一个命令行工具,转换成文本信息。tesseract-ocr官方下载据说曾经的图像识别能力排名第三。tesseract-ocr中文版可以识别多种格式的图像文件并将其转换成文本,目前已支持60多种语言(包括中文)。 Tesseract最初由HP公司开发,后来由Google维护,目前发布在Googel Project上。
windows下的安装非常简单,直接安装可执行程序即可。当你选择安装各类语言之时,则需要一个稍微耗时的等待操作,比如下图中所示的信息:

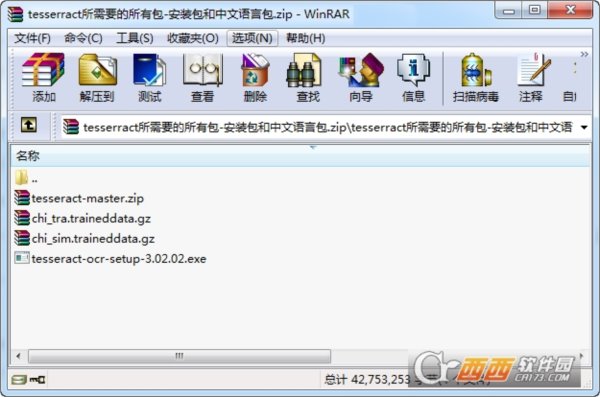
下载完后进行安装,默认情况下安装程序会给你配置系统环境变量,以指向安装目录(之后可以通过DOS界面在任意目录运行tesseract)。安装完成后目录如下:

附录:
tessdata 目录存放的是语言字库文件,和在命令行界面中可能用到的参数所对应的文件. 这个安装程序默认包含了英文字库。
使用Tessract-OCR引擎识别验证码
打开DOS界面,输入tesseract:

如果出现如上输出,表示安装正常。
我准备了一张验证码code.jpg放在D盘根目录下 ,上图:
,上图:

结果为:

附录:
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile.
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
例如:
tesseract code.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
-psm 7 表示告诉tesseract code.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdata\configs 和 tessdata\tessconfigs 目录下的文件名
 page player查看
page player查看 2020年日历庚子年【鼠年】及万年历Excel版查看
2020年日历庚子年【鼠年】及万年历Excel版查看 WPS Office 2019专业版(提取纯净版)查看
WPS Office 2019专业版(提取纯净版)查看 峰软ERP暖通行业专用版查看
峰软ERP暖通行业专用版查看 小筑笔记PC版查看
小筑笔记PC版查看 管友服装管理软件查看
管友服装管理软件查看 NoteFirst文献管理软件查看
NoteFirst文献管理软件查看 微选小店上货助手查看
微选小店上货助手查看 营销神器(网络推广工具)查看
营销神器(网络推广工具)查看 零一工具箱查看
零一工具箱查看 discuz文章采集器查看
discuz文章采集器查看 PPT计时器查看
PPT计时器查看 Onetastic查看
Onetastic查看 WPS Office 2019正式版查看
WPS Office 2019正式版查看 Excel对比工具(Synkronizer for Excel 11)查看
Excel对比工具(Synkronizer for Excel 11)查看 效率时间工具(Stayfoucused pro)查看
效率时间工具(Stayfoucused pro)查看 坚石宿舍管理系统查看
坚石宿舍管理系统查看 101教育ppt软件查看
101教育ppt软件查看 DPS设计印刷分享软件 2020查看
DPS设计印刷分享软件 2020查看 XMind ZEN免费安装版查看
XMind ZEN免费安装版查看 阿里云会议电脑版查看
阿里云会议电脑版查看 Nitro PDF Professional查看
Nitro PDF Professional查看 三茅招聘 2019查看
三茅招聘 2019查看 office 2019中文专业增强版查看
office 2019中文专业增强版查看智百盛汽车维修管理软件完整免费版办公软件Mv8.0官方版
查看Somedraw办公软件M0.1.0官方版
查看CNKI工具书办公软件Mv2.1官方版
查看WPS Office 2019西北大学教育版办公软件MV11.8.2.8411安装无限制可用版本
查看Mbus数据采集系统办公软件.87Mv2.0 绿色版
查看黄金屋进销存软件办公软件M2.0官方版
查看O3区块链办公软件M1.2.2官方版
查看飞扬动力广告公司管理软件基础版办公软件M2.6.0.646 官方版
查看迷你电脑取色器ColorPix办公软件.30M免费版
查看金山WPS2013个人版办公软件MV9.1.0.4693免费版
查看Power-user办公软件Mv1.6.565.0免费版
查看联信UM电脑客户端办公软件Mv5.6 最新版
查看仁润汽车融资租赁管理系统办公软件Mv2.8最新版
查看个人记账理财工具办公软件Mv6.1.0.5191中文版
查看华强云PC客户端办公软件M3.4.0官方版
查看UI设计语言(Ant Design)办公软件Mv4.4.1官方版
查看演讲比赛计时器办公软件.84M1.2
查看天跃之星营销优化软件办公软件Mv9.0.2013官方版
查看印象笔记(EverNote)办公软件Mv6.24.1.8906官方最新版
查看Microsoft Office 2010中文版 32/64位办公软件Moffice2010中文版
查看PHP在线小说生成软件办公软件M
查看千帆掌柜电脑版办公软件Mv2.1官方版
查看PCB制作换算器办公软件.16M1.0绿色免费版
查看KanCloud Editor办公软件M1.0.3官方版
查看点击查看更多